J’ai répondu rapidement jeudi soir, mais il se faisait tard. Voici des éléments plus poussés sur la question. Attention, là c’est un peu compliqué, un peu long, moins philosophiques et plus mathématique.
Disclémeur :
Je ne suis pas très à l’aise sur ces questions et il se peut qu’il y ait des erreurs. Une des questions à laquelle je ne saurais pas bien répondre, c’est de savoir par quel argument on démontre que le QI peut revêtir une certaine linéarité. D’après ma compréhension, on peut partir dans deux directions :
- à l’intérieur du QI, en regardant de près comment il est construit,
- vers l’extérieur, en regardant ce qui sert à sa validation.
Mon message précédent suggère que le QI n’est pas linéaire, car construit sur des indices pour lesquels la linéarité n’a tout simplement pas de sens. Ce n’est pas qu’ils soient non-linéaires, mais qu’on ne peut même pas parler de linéarité. C’est beaucoup plus radical.
Plutôt que d’aller voir à l’intérieur du QI, une autre direction est d’étudier sa validation externe. J’en ai déjà parlé : quand on établit une mesure en science, on doit vérifier que :
1) l’outil qu’on a créé a bien valeur de mesure
2) si c’est le cas, qu’il mesure bien ce qu’on souhaite mesurer.
En l’absence d’étalon, on en est réduit à comparer une mesure comme la WAIS à d’autres mesures de l’intelligence, comme la réussite scolaire, professionnelle, etc. Si on était capable de mesurer proprement ces diverses mesures externes, d’établir une corrélation assez précise avec le QI, et qu’on se rendait compte qu’à chaque fois, il y a une certaine proportionnalité entre le QI et ces mesures issues du monde réel, alors on pourrait se dire que notre outil « QI » est bien un indicateur linéaire de compétences dans le monde réel.
Mais cette sorte d’idéal va butter contre le réel, pour un grand nombre de raisons.
La première, c’est que les mesures externes considérées comme révélatrices de l’intelligence constituent un postulat : des hypothèses non démontrées. Il n’est pas idiot de considérer que la réussie scolaire ou professionnelle sont liées à l’intelligence. Mais ça n’est pas une preuve.
Un deuxième point, c’est que pour établir une linéarité, il faut mesurer « la réussite scolaire » ou « la réussite professionnelle ». Par exemple, on peut mesurer la réussite scolaire par le nombre d’années d’études. On peut mesurer la réussite professionnelle par le salaire après 10 ans d’ancienneté. Je ne vais pas faire ces débats-là, simplement dire que c’est très fortement sujet à débat !
Et même si on parvenait à un certain consensus, et qu’on puisse comparer le QI à plusieurs mesures représentant des capacités dans le monde réel, il y a peu de chances qu’on puisse aller dans le détail et dire qu’on a une progression forte entre 70 et 115 de QI, puis modeste entre 115 et 130, puis à nouveau un peu plus marquée au-delà. Si on arrive à décrire une tendance générale, on sera déjà bien heureux. On est dans le domaine des sciences sociales, avec des mesures extrêmement bruitées et des corrélations assez faibles.
Dans les graphes ci-dessous, j’ai tracé l’évolution d’une capacité fictive (en ordonnée) en fonction du QI (abscisse). Le modèle qui a servi à générer les données est le même pour les trois graphes, c’est le trait bleu (linéaire par morceau) sur le premier et second graphe. Évidemment, en pratique, on n’a pas la courbe bleue, on n’a que les nuages de points, et on cherche à reconstruire cette courbe bleue.
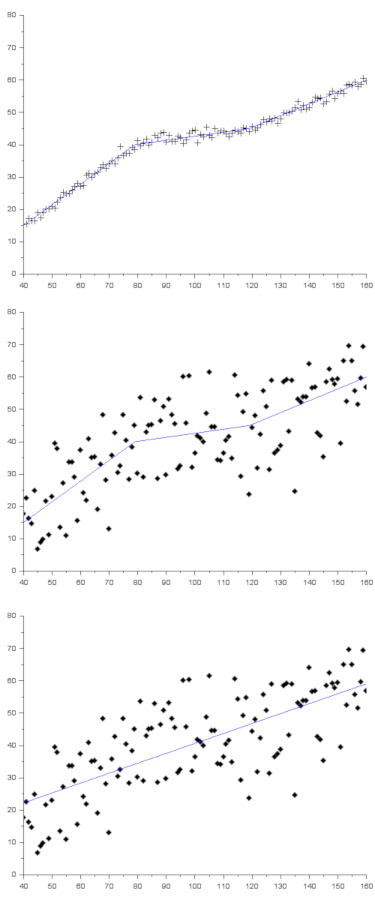
Dans le graphe du haut, le bruit est très faible. C’est le genre de comportement qu’on obtient en science physique avec des phénomènes déterministes. Dans une telle situation, il est raisonnable d’affirmer que l’évolution de la capacité fictive est linéaire par morceaux.
Dans le graphe du milieu, le bruit de mesure est beaucoup plus important. Il n’y a quasiment aucune chance qu’on puisse retrouver la vraie courbe bleue. On aura plutôt tendance à proposer un modèle linéaire (graphe du bas). Pourtant la courbe bleue du bas est fausse, le modèle qui a généré ce graphe est toujours linéaire par morceau. Mais le bruit est tel qu’on ne pourra que détecter la tendance générale, pas les petites variations par morceau.
On pourrait chercher autre chose qu’un simple modèle linéaire. Mais quel modèle proposer ? Une équation du second degré ? Un modèle linéaire par morceau, mais avec deux morceaux ? Trois ? Quatre ? Et sur quel intervalle s’applique chaque morceau ?
On peut toujours trouver un polynôme qui passe par tous les points mesurés (pour ceux que ça intéresse, cherchez les interpolations par polynômes de Lagrange). C’est ce que j’ai illustré ci dessous.
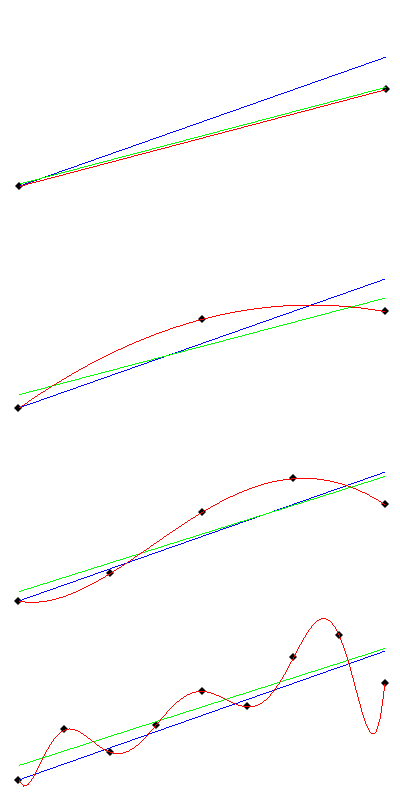
En allant vers le bas, le nombre de mesures dans l’expérience augmente. A chaque fois, le phénomène réel (qu’on ignore) est tracé en bleu. En vert, c’est la régression linéaire faite à partir des mesures bruitées (les points noirs). En rouge, c’est le polynôme de Lagrange qui passe par tous les points.
Si on calcule l’erreur de prédiction, on s’apercevra que celle du polynôme est nulle, car il passe exactement par chaque point. Le hic, c’est qu’il n’y a aucune stabilité quand on augmente le nombre de points : le polynôme obtenu avec 5 points n’a rien à voir avec celui obtenu avec 9 points. Le polynôme tend à osciller de plus en plus. On a beau avoir un « R carré » nul, on n’est pas en train de faire une régression, on est juste en train d’interpoler le bruit de fond. Dans cet exemple, présupposer un modèle linéaire est plus pertinent qu’un modèle plus complexe, quand bien même le « R carré » est plus faible.
Le principe d’une régression linéaire, c’est qu’on prend pour postulat que le modèle sous-jacent est linéaire, et que les écarts sont dus à des erreurs de mesures. Si on se plante totalement et que les mesures ne sont pas trop bruitées, on s’en rendra compte. Mais si le modèle n’est pas très éloigné d’un comportement linéaire et que les mesures sont très bruitées, on ne saura pas dire dans quelle ampleur on a fait passer à tort une partie du comportement réel dans des erreurs de mesures.
On se retrouve coincé : si on suppose que le modèle est linéaire, ben évidemment on ne risque pas de voir les non linéarités ! Mais si on chercher à faire « fitter » un modèle plus complexe qu’une loi affine, on est peut-être en train d’interpoler le bruit de fond et de proposer un modèle très éloigné du réel, alors qu’une simple droite serait plus juste.
Voilà pourquoi il y a très peu de chances de pouvoir observer autre chose que des phénomènes très francs, et encore on restera très retenus sur les conclusions. C’est un peu ce qui se passe pour la relation entre QI et Créativité. Il se pourrait qu’il y ait une limite autour d’un QI 120 à peu près, au-delà de laquelle le supplément de QI n’apporte pas de supplément de créativité à grande échelle. Mais si vous jetez un œil à cette étude, vous verrez que c’est loin d’être une certitude :
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3682183/
Si on se rendait compte de manière fiable qu’au delà du même seuil de QI, par exemple 120, il n’y a plus de gain de créativité, ni d’accroissement de salaire, ni d’allongement des études, et que tout pleins de facteurs représentatifs du monde réel tendent à plafonner, alors on pourrait se dire que toutes les personnes avec un QI supérieur à 120 ont peu ou prou la même intelligence, et que les différences mesurées dans un cabinet de psy ne se traduisent par rien de concret dans la vie réelle. Mais on est très, très loin de ça.
Voilà, j’espère avoir convaincu que cette question de la linéarité du QI est très complexe, et qu’en l’état actuel des connaissances, elle n’a tout simplement pas beaucoup de sens.